🚀 My Projects
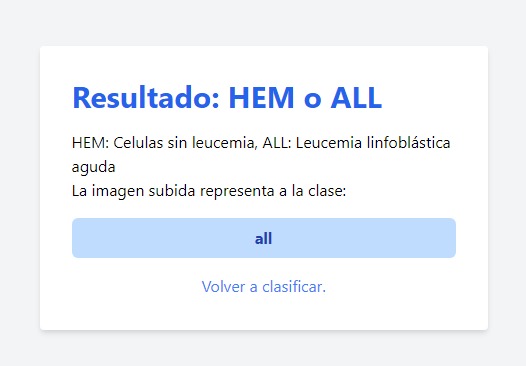
🩸 Acute Lymphoblastic Leukemia Classifier
This project focuses on the early detection and classification of Acute Lymphoblastic Leukemia (ALL), a type of cancer that affects white blood cells, using machine learning and computer vision. The goal is to assist medical professionals by offering a tool that automatically classifies leukemia cells based on uploaded images, improving diagnostic accuracy and speed. This classifier integrates advanced deep learning models to identify and categorize ALL into various stages, potentially aiding in timely medical intervention. 💻
🔬 Key Features
The project is built using TensorFlow for deep learning, scikit-image for advanced image processing, and Flask to provide a web interface that makes it accessible to medical professionals. It consists of two primary machine learning models: one for identifying whether a cell is normal ('hem') or leukemic ('all'), and another for classifying the disease into stages: 'Benign', 'Early', 'Pre', and 'Pro'. The user-friendly interface allows doctors to securely upload patient images, receive real-time classification results, and store these results for further analysis. The project not only classifies but also stores and manages these results in a database for future reference and tracking.
💡 Technologies
- Flask: For the web application and user interface
- TensorFlow: To power the machine learning models
- scikit-image: For handling image processing tasks
- SQLite: Database for securely storing classification results
🚀 How to Use
To use this classifier, users can upload leukemia cell images through the web application. The system then processes these images and runs them through the machine learning models to classify the leukemia type and stage. The results are displayed on the screen and saved to the application's database, where users can view previous classifications and data. This project also supports secure user authentication, ensuring that only authorized medical personnel can access sensitive diagnostic features.
🔗 GitHub Repository
📦 Intelligent Inventory Management with Machine Learning
This project focuses on improving inventory forecasting and accuracy for a fabric retail company. Using machine learning, it predicts future stock demands to reduce excess inventory and prevent stockouts. 🛠️
📊 Project Highlights
Developed using Python, this system integrates models such as ARIMA and Facebook Prophet to predict future inventory levels. By analyzing past sales data, the project helps businesses streamline their stock management, prevent overstocking, and ensure that stockouts are minimized. 🌐
🛠️ Tools & Technologies
- Pandas and NumPy for data manipulation
- Scikit-learn for machine learning models
- Facebook Prophet for time series forecasting
📚 Project Methodology
This project follows the CRISP-DM (Cross-Industry Standard Process for Data Mining) methodology, a structured approach that includes market and data understanding, data preparation, modeling, and evaluation. It ensures that the predictive models align with business objectives and are capable of delivering accurate inventory forecasts.
🚀 How It Works
By analyzing historical sales and inventory data, the project forecasts future stock needs and offers actionable insights for maintaining the right inventory levels. The system continuously updates its predictions, allowing businesses to adapt to changing market conditions. With a deployment-ready pipeline, it integrates into existing inventory systems to automate stock management processes.
🔗 GitHub Repository
💬 Complaint Classification with NLP
This project uses natural language processing (NLP) and machine learning models to classify customer complaints into predefined categories, improving response times for customer service teams. The system is optimized for Spanish-language data and achieves impressive classification accuracy. 🤖
🔍 Key Highlights
Using techniques such as TF-IDF vectorization and models like LinearSVC, Logistic Regression, and Random Forest, this project classifies complaints with high precision. The best-performing model, LinearSVC, achieved an accuracy of 100%. 🌍
🛠️ Tools & Technologies
- Python for data preprocessing and modeling
- Scikit-learn for implementing machine learning algorithms
- TF-IDF for text vectorization in Spanish
📈 Key Contributions
- Automated classification with an accuracy of 100% using LinearSVC
- Reduced response time for customer service by automating complaint sorting
🔊 Azure-Voice-to-Text
This project utilizes Azure Cognitive Services to create a web application that records, transcribes, and analyzes medical consultations. It integrates Azure's text-to-speech and text classification APIs, aiming to streamline medical consultations and provide actionable insights from transcribed data.
🔍 Key Highlights
The application allows recording of both in-person and virtual consultations, converts audio to text with Azure's text-to-speech service, and analyzes the text using Azure's AI capabilities to provide valuable insights.
🛠️ Tools & Technologies
- Flask for the web application framework
- Azure Cognitive Services for text-to-speech and text classification
- Python for application logic and Azure integration
📈 Future Enhancements
- Integration with Electronic Health Records (EHR)
- Enhanced security features
- Support for additional languages

🧺 Basic Food Basket Price Comparison
This project compares the prices of the basic food basket across the top five supermarkets in Paraguay. Using web scraping techniques, the prices of various items are analyzed to determine the most cost-effective supermarket.
🔍 Key Highlights
The project utilizes web scraping to gather data from supermarket websites, processes and analyzes this data with Python libraries, and presents the results through a Flask web application.
🛠️ Tools & Technologies
- Python for web scraping and data analysis
- BeautifulSoup and Requests for scraping data
- Pandas and Numpy for data manipulation and analysis
- Flask for presenting results on a web page
📈 Screenshots
🔗 GitHub Repository
📊 Best Machine Learning Models
This repository showcases 10 different machine learning models applied to a dataset for analysis and predictions. It serves as a comprehensive resource for understanding various models and their applications in real-world scenarios.
🔍 Key Highlights
Includes models such as Linear Regression, Logistic Regression, Decision Trees, and Neural Networks. The notebook provides clear examples and code for training, testing, and making predictions with these models.
🛠️ Tools & Technologies
- Python for coding and model implementation
- Jupyter Notebooks for interactive coding
- Scikit-learn for machine learning algorithms
📚 Educational Resource
This project is ideal for beginners and provides a practical overview of different machine learning algorithms and their implementations.
🔗 GitHub Repository